11
0
33
新手上路
举报
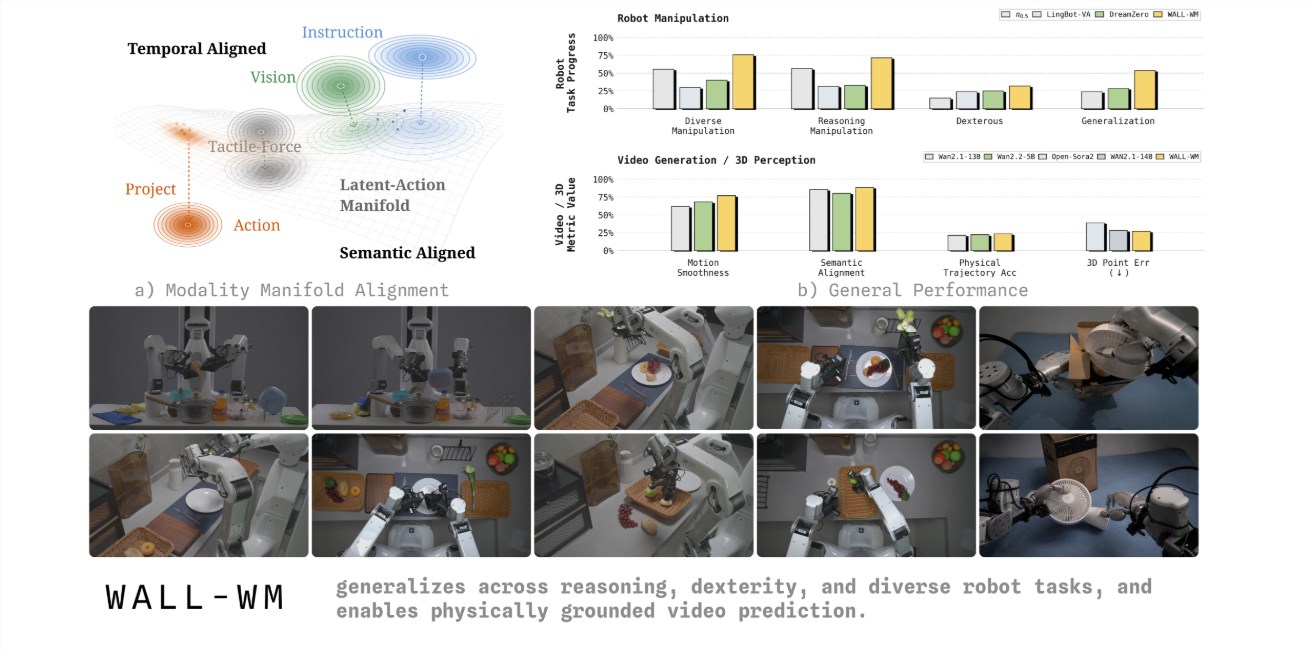
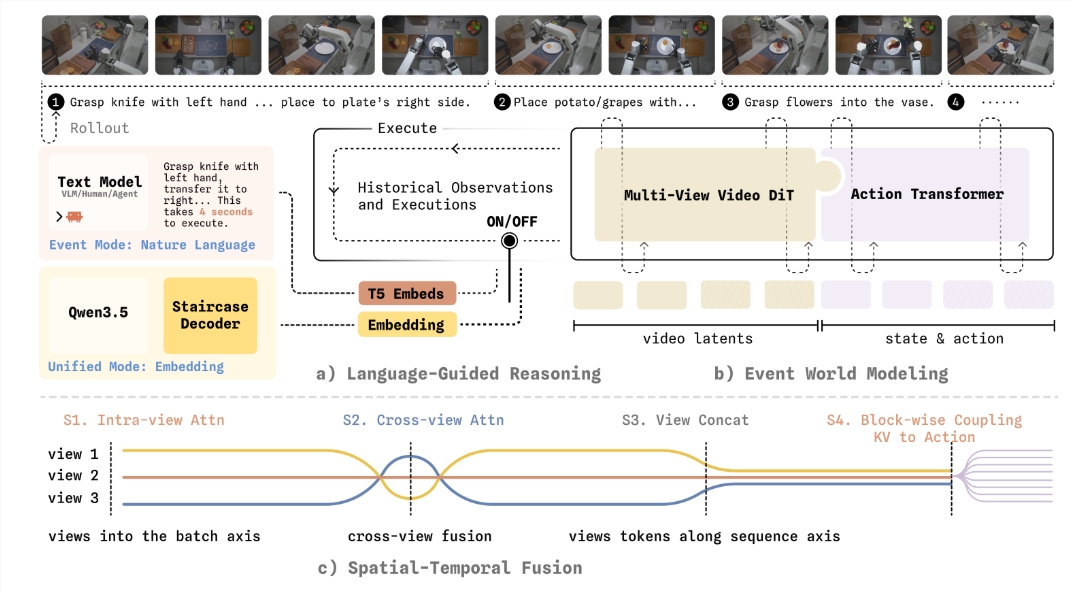
老剧场 发表于 2026-5-29 17:05 机器人告别“逐帧学动作”!全球首个事件级具身智能世界模型发布 5月29日,自变量机器人团队正式发布了全 ...
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
相关侵权、举报、投诉及建议等,请发 E-mail:admin#boss.im
Powered by Discuz! X5.1 Licensed © 2001-2026 Discuz! Team.|浙ICP备2022024777号-14


 发表于
发表于