19
0
57
注册会员
举报
-2
-4
限制会员
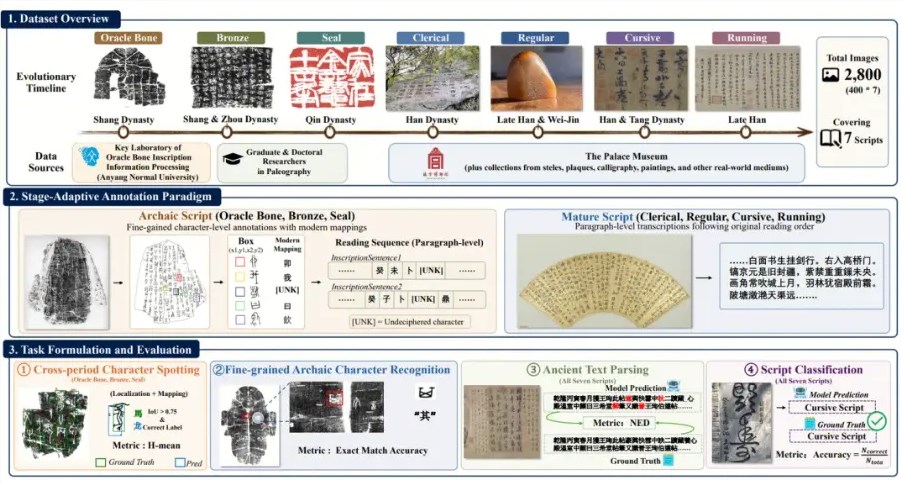
时光机 发表于 2026-5-19 18:00 视觉大模型遭遇滑铁卢:首个中国古文字OCR评测基准开源顶尖的人工智能不仅要能看懂屏幕上跳动的现代代码, ...
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
相关侵权、举报、投诉及建议等,请发 E-mail:admin#boss.im
Powered by Discuz! X5.1 Licensed © 2001-2026 Discuz! Team.|浙ICP备2022024777号-14


 发表于 2026-5-19 18:00:25
发表于 2026-5-19 18:00:25