20
0
60
注册会员
举报
新手上路
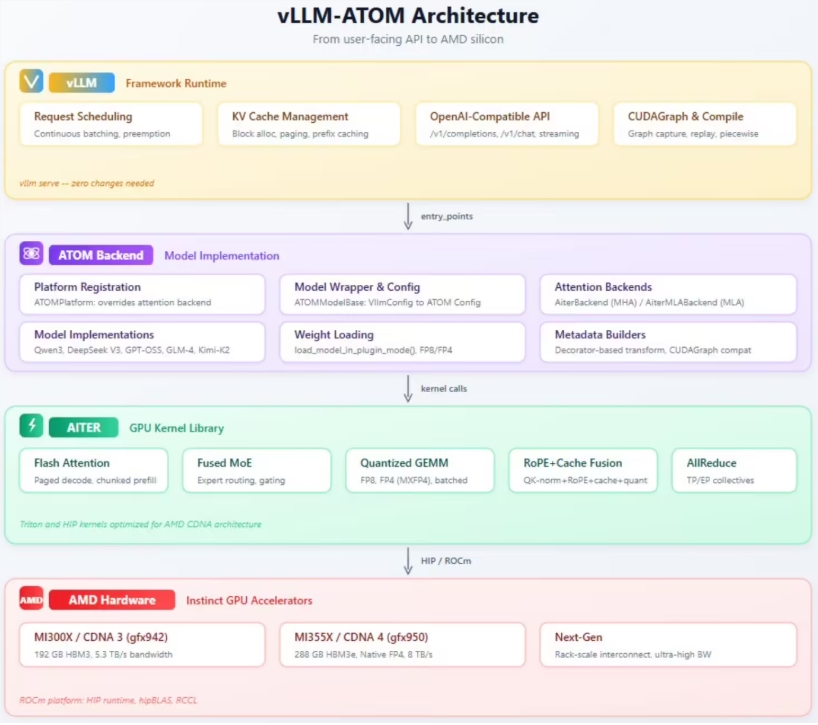
老邮筒 发表于 2026-5-12 12:08 加速国产大模型:AMD推出vLLM-ATOM插件大幅提升推理效率AMD近日正式发布了专为大语言模型部署设计的vLLM-AT ...
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
相关侵权、举报、投诉及建议等,请发 E-mail:admin#boss.im
Powered by Discuz! X5.1 Licensed © 2001-2026 Discuz! Team.|浙ICP备2022024777号-14


 发表于 2026-5-12 12:08:58
发表于 2026-5-12 12:08:58